| Бета-біноміальний розподіл |
|---|
|
Функція ймовірностей 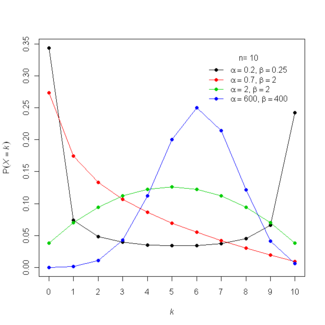 |
|
Функція розподілу ймовірностей  |
| Параметри |
n ∈ N0 — число випробувань
 (дійсне) (дійсне)
 (дійсне) (дійсне) |
|---|
| Носій функції |
k ∈ { 0, …, n } |
|---|
| Розподіл імовірностей |

де  — Бета-функція — Бета-функція |
|---|
| Функція розподілу ймовірностей (cdf) |

де 3F2(a;b;x) — узагальнена гіпергеометрична функція
 |
|---|
| Середнє |
 |
|---|
| Дисперсія |
 |
|---|
| Коефіцієнт асиметрії |
 |
|---|
| Коефіцієнт ексцесу |
See text |
|---|
| Твірна функція моментів (mgf) |
 де де  — гіпергеометрична функція — гіпергеометрична функція |
|---|
| Характеристична функція |

 |
|---|
| Генератриса (pgf) |

|
|---|
У теорії ймовірностей і статистиці, бета-біноміальний розподіл являє собою сімейство дискретних імовірнісних розподілів на скінченному носії невід'ємних цілих чисел, що виникає коли ймовірність успіху в кожному з фіксованих чи відомого числа випробувань Бернуллі або невідома, або є випадковою. Бета-біноміальний розподіл — це біноміальний розподіл, у якому ймовірність успіху в кожному з n випробувань не є фіксованою, а є випадковою реалізацією бета-розподіленої випадкової величини. Розподіл часто використовується в байєсівській статистиці, емпіричних методах Байєса та класичній статистиці для виявлення наддисперсії в біноміально розподілених даних.
Він зводиться до звичайного розподілу Бернуллі, коли n=1. Для α=β=1, це дискретний рівномірний розподіл від 0 до n. Він також як завгодно добре наближує біноміальний розподіл для великих α і β . Аналогічно, зводиться негативного біноміального розподілу при великими значеннями β і n. Бета-біноміальний є одновимірною версією мультиноміального розподілу Діріхле, оскільки біноміальний та бета-розподіл є одновимірними версіями мультиноміального та розподілу Діріхле відповідно.
Особливий випадок, коли α і β є цілими числами, також відомий як негативний гіпергеометричний розподіл.
Бета-розподіл — це спряжений розподіл біноміального розподілу . Цей факт дозволяє аналітично вивести складений розподіл, якщо вважати параметр  у біноміальному розподілі як випадкову реалізацію бета-розподіленої випадкової величини. А саме, якщо
у біноміальному розподілі як випадкову реалізацію бета-розподіленої випадкової величини. А саме, якщо

тоді

де Bin( n, p ) означає біноміальний розподіл, а де p — випадкова величина з бета-розподілом.
![{\displaystyle {\begin{aligned}\pi (p\mid \alpha ,\beta )&=\mathrm {Beta} (\alpha ,\beta )\\[5pt]&={\frac {p^{\alpha -1}(1-p)^{\beta -1}}{\mathrm {B} (\alpha ,\beta )}}\quad {\text{for }}0\leq p\leq 1,\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b774219c2be5e5ef2db8114187ce996587b10529)
тоді складений розподіл визначається як
![{\displaystyle {\begin{aligned}f(k\mid n,\alpha ,\beta )&=\int _{0}^{1}L(p\mid k)\pi (p\mid \alpha ,\beta )\,dp\\[6pt]&={n \choose k}{\frac {1}{\mathrm {B} (\alpha ,\beta )}}\int _{0}^{1}p^{k+\alpha -1}(1-p)^{n-k+\beta -1}\,dp\\[6pt]&={n \choose k}{\frac {\mathrm {B} (k+\alpha ,n-k+\beta )}{\mathrm {B} (\alpha ,\beta )}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6509c3d1e2dda9163ef5353ad514af33e0f9ae96)
Використовуючи властивості бета-функції, вираз можна переписати

Бета-біноміальний розподіл також можна пояснити за допомогою моделі урн для цілих додатних значень α і β, відомої як модель урни Полі. Зокрема, уявіть собі урну, що містить α червоних кульок та β чорних кульок, звідки їх виймають навмання. Якщо дістали червону кульку, то до урни повертають дві червоні кульки. Аналогічно з чорними кульками, якщо дістають чорну кулю, то натомість в урну повертають дві чорні. Якщо експеримент повторити n разів, то ймовірність отримати k червоних куль буде мати бета-біноміальний розподіл з параметрами n, α і β .
Якщо випадкові випробування здійснюються з простою заміною (повертають тільки одну, ту що щойно дістали, кульку), то маємо справу з біноміальним розподілом, а якщо експеримент здійснюються без заміни, то спостерігаємо реалізацію гіпергеометрично розподіленої випадкової величини.
Перші три моменти
![{\displaystyle {\begin{aligned}\mu _{1}&={\frac {n\alpha }{\alpha +\beta }}\\[8pt]\mu _{2}&={\frac {n\alpha [n(1+\alpha )+\beta ]}{(\alpha +\beta )(1+\alpha +\beta )}}\\[8pt]\mu _{3}&={\frac {n\alpha [n^{2}(1+\alpha )(2+\alpha )+3n(1+\alpha )\beta +\beta (\beta -\alpha )]}{(\alpha +\beta )(1+\alpha +\beta )(2+\alpha +\beta )}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d8b08123d7cc1c1b79069bd5d3d3f78776de5945)
Ексцес задається формулою
![{\displaystyle \beta _{2}={\frac {(\alpha +\beta )^{2}(1+\alpha +\beta )}{n\alpha \beta (\alpha +\beta +2)(\alpha +\beta +3)(\alpha +\beta +n)}}\left[(\alpha +\beta )(\alpha +\beta -1+6n)+3\alpha \beta (n-2)+6n^{2}-{\frac {3\alpha \beta n(6-n)}{\alpha +\beta }}-{\frac {18\alpha \beta n^{2}}{(\alpha +\beta )^{2}}}\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8a0a324a1e2fa8215447cc6cf5761738050f371f)
Позначимо  , тоді середнє можна записати як
, тоді середнє можна записати як

і дисперсія як
![{\displaystyle \sigma ^{2}={\frac {n\alpha \beta (\alpha +\beta +n)}{(\alpha +\beta )^{2}(\alpha +\beta +1)}}=n\pi (1-\pi ){\frac {\alpha +\beta +n}{\alpha +\beta +1}}=n\pi (1-\pi )[1+(n-1)\rho ]\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/991ce686abc74a57c81097ad07c2b8eca60b5178)
де  . Параметр
. Параметр  відомий як кореляція «всередині класу» або «внутрішньокластерна» кореляція. Саме ця позитивна кореляція призводить до надмірної дисперсії.
відомий як кореляція «всередині класу» або «внутрішньокластерна» кореляція. Саме ця позитивна кореляція призводить до надмірної дисперсії.
Методом моментів можна отримати оцінки, а саме запишемо перший і другий моменти бета-біноміального розподілу
![{\displaystyle {\begin{aligned}\mu _{1}&={\frac {n\alpha }{\alpha +\beta }}\\[6pt]\mu _{2}&={\frac {n\alpha [n(1+\alpha )+\beta ]}{(\alpha +\beta )(1+\alpha +\beta )}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8823da9a5ad741ae07796e17e601c4f0d325013b)
і прирівняємо ці нецентральні моменти до першого та другого нецентрального моменту вибірки відповідно
![{\displaystyle {\begin{aligned}{\widehat {\mu }}_{1}&:=m_{1}={\frac {1}{N}}\sum _{i=1}^{N}X_{i}\\[6pt]{\widehat {\mu }}_{2}&:=m_{2}={\frac {1}{N}}\sum _{i=1}^{N}X_{i}^{2}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8ecd69c69958e11798bf6777604329cf654f18da)
розв’яжемо для α і β і отримуємо
![{\displaystyle {\begin{aligned}{\widehat {\alpha }}&={\frac {nm_{1}-m_{2}}{n({\frac {m_{2}}{m_{1}}}-m_{1}-1)+m_{1}}}\\[5pt]{\widehat {\beta }}&={\frac {(n-m_{1})(n-{\frac {m_{2}}{m_{1}}})}{n({\frac {m_{2}}{m_{1}}}-m_{1}-1)+m_{1}}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/74abfcda5a1906399e3218f8a67446428ad1d557)
Ці оцінки можуть виглядати безглуздо негативними, що є доказом того, що дані є або нерозподілені зовсім або розподілені недостатньо у порівнянні до біноміального розподілу. У цьому випадку біноміальний розподіл і гіпергеометричний розподіл є альтернативними кандидатами відповідно.
Хоч формула оцінки методом максимальної правдоподібності є непрактичною, враховуючи, що щільність складається із звичних функцій (гамма-функції та/або бета-функції), їх можна легко знайти за допомогою прямої чисельної оптимізації. Оцінки максимальної правдоподібності на основі емпіричних даних можуть бути обчислені за допомогою загальних методів підгонки мультиноміальних розподілів Полі, методи для яких описані в (Minka 2003). Пакет R VGAM через функцію vglm, використовуючи метод максимальної правдоподібності, полегшує оцінку УЛМ моделей з результатами, розподіленими за бета-біноміальним розподілом. Немає явної вимоги аби n було фіксованим впродовж спостережень.
Наведені нижче дані показують кількість дітей чоловічої статі серед перших 12 дітей у 6115 сім'ях з 13-ма дітьми, взятих із лікарняних карт Саксонії 19 століття (Sokal and Rohlf, с.59 від Ліндсі). 13-ту дитину ігнорують, щоб пом’якшити ефект від того, що родина перестала пробувати завести дитину за умови досягнення бажаної статі.
| Хлопчики
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
| Родини
|
3
|
24
|
104
|
286
|
670
|
1033
|
1343
|
1112
|
829
|
478
|
181
|
45
|
7
|
Перші два емпіричні моменти

тому оцінка методом моментів

Оцінка методом максимальної ймовірності можна вирахувати чисельними методами

і максимальна логарифмічна правдоподібність

звідси знаходимо AIC

AIC для конкуруючої біноміальної моделі є AIC = 25070.34, таким чином, бачимо, що бета-біноміальна модель забезпечує кращу відповідність даним, тобто присутні докази надмірної дисперсії. Трайверс і Віллард висувають теоретичне обгрунтування гетерогенності (також відомої як «розривність») у гендерній схильності нащадків ссавців (тобто надмірна дисперсність).
Краща припасовка особливо добре помітна в хвостах
| Хлопці
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
| Спостережувані родини
|
3
|
24
|
104
|
286
|
670
|
1033
|
1343
|
1112
|
829
|
478
|
181
|
45
|
7
|
| Очікуваний число (бета-біноміальний)
|
2.3
|
22.6
|
104.8
|
310.9
|
655.7
|
1036.2
|
1257.9
|
1182.1
|
853.6
|
461.9
|
177,9
|
43.8
|
5.2
|
| Очікуваний число ( біноміальний p = 0,519215)
|
0.9
|
12.1
|
71.8
|
258.5
|
628.1
|
1085.2
|
1367.3
|
1265.6
|
854.2
|
410,0
|
132.8
|
26.1
|
2.3
|
Зручно перепараметризувати розподіли так, щоб очікуване середнє значення апріорного розподілу було одним параметром, нехай
![{\displaystyle {\begin{aligned}\pi (\theta \mid \mu ,M)&=\operatorname {Beta} (M\mu ,M(1-\mu ))\\[6pt]&={\frac {\Gamma (M)}{\Gamma (M\mu )\Gamma (M(1-\mu ))}}\theta ^{M\mu -1}(1-\theta )^{M(1-\mu )-1}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9513115288dd1d5b478ac26cdae886a65641f368)
де
![{\displaystyle {\begin{aligned}\mu &={\frac {\alpha }{\alpha +\beta }}\\[6pt]M&=\alpha +\beta \end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0710866719b771618db2827f0fd6bca15a88b1b7)
таким чином
![{\displaystyle {\begin{aligned}\operatorname {E} (\theta \mid \mu ,M)&=\mu \\[6pt]\operatorname {Var} (\theta \mid \mu ,M)&={\frac {\mu (1-\mu )}{M+1}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a60de1264421c9162224d9e63974b79c9c5f1c1c)
Апостеріорний розподіл ρ ( θ | k ) також є бета-розподілом:
![{\displaystyle {\begin{aligned}\rho (\theta \mid k)&\propto \ell (k\mid \theta )\pi (\theta \mid \mu ,M)\\[6pt]&=\operatorname {Beta} (k+M\mu ,n-k+M(1-\mu ))\\[6pt]&={\frac {\Gamma (M)}{\Gamma (M\mu )\Gamma (M(1-\mu ))}}{n \choose k}\theta ^{k+M\mu -1}(1-\theta )^{n-k+M(1-\mu )-1}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c43077d17fa635bd89822f79b4d7edd66616ce39)
І

тоді як граничний розподіл m ( k | μ, M ) визначається як
![{\displaystyle {\begin{aligned}m(k\mid \mu ,M)&=\int _{0}^{1}\ell (k\mid \theta )\pi (\theta \mid \mu ,M)\,d\theta \\[6pt]&={\frac {\Gamma (M)}{\Gamma (M\mu )\Gamma (M(1-\mu ))}}{n \choose k}\int _{0}^{1}\theta ^{k+M\mu -1}(1-\theta )^{n-k+M(1-\mu )-1}\,d\theta \\[6pt]&={\frac {\Gamma (M)}{\Gamma (M\mu )\Gamma (M(1-\mu ))}}{n \choose k}{\frac {\Gamma (k+M\mu )\Gamma (n-k+M(1-\mu ))}{\Gamma (n+M)}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/eaa1e1bd62615cdbe3fef46e7a187b5237404ffa)
Підставляючи назад M і μ, в термінах  і
і  , отримаємо:
, отримаємо:

який і є очікуваним бета-біноміальним розподілом з параметрами  і .
і .
Ми також можемо використати метод повторних матсподівань, щоб знайти очікуване значення граничних моментів. Запишемо нашу модель як двоступеневу модель складної вибірки. Нехай k i — кількість успіхів із n i спроб для події i :
![{\displaystyle {\begin{aligned}k_{i}&\sim \operatorname {Bin} (n_{i},\theta _{i})\\[6pt]\theta _{i}&\sim \operatorname {Beta} (\mu ,M),\ \mathrm {i.i.d.} \end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/21d6d5bcb66e8ee3097d5b0fbae6ebea6e69d28e)
Можемо знайти покрокові оцінки моментів для середнього та дисперсії, використовуючи моменти для розподілів у двокроковій моделі:
![{\displaystyle \operatorname {E} \left({\frac {k}{n}}\right)=\operatorname {E} \left[\operatorname {E} \left(\left.{\frac {k}{n}}\right|\theta \right)\right]=\operatorname {E} (\theta )=\mu }](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a111b29de189969aa34cc5790268d6bf7b03c49)
![{\displaystyle {\begin{aligned}\operatorname {var} \left({\frac {k}{n}}\right)&=\operatorname {E} \left[\operatorname {var} \left(\left.{\frac {k}{n}}\right|\theta \right)\right]+\operatorname {var} \left[\operatorname {E} \left(\left.{\frac {k}{n}}\right|\theta \right)\right]\\[6pt]&=\operatorname {E} \left[\left(\left.{\frac {1}{n}}\right)\theta (1-\theta )\right|\mu ,M\right]+\operatorname {var} \left(\theta \mid \mu ,M\right)\\[6pt]&={\frac {1}{n}}\left(\mu (1-\mu )\right)+{\frac {n-1}{n}}{\frac {(\mu (1-\mu ))}{M+1}}\\[6pt]&={\frac {\mu (1-\mu )}{n}}\left(1+{\frac {n-1}{M+1}}\right).\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/24f1793e7dd1ca9ebddb7e8986ba819b64c96cb1)
(Тут ми використовували закон повного матсподівання і закон повної дисперсії.)
Знайдемо точкові оцінки  і
і  . Розрахункове середнє
. Розрахункове середнє  розраховується з вибірки
розраховується з вибірки

Оцінку гіперпараметра M можна обчислити використовуючи оцінки моментів для дисперсії з двокрокової моделі:
![{\displaystyle s^{2}={\frac {1}{N}}\sum _{i=1}^{N}\operatorname {var} \left({\frac {k_{i}}{n_{i}}}\right)={\frac {1}{N}}\sum _{i=1}^{N}{\frac {{\widehat {\mu }}(1-{\widehat {\mu }})}{n_{i}}}\left[1+{\frac {n_{i}-1}{{\widehat {M}}+1}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bab04920b21118ce1c9e163ac2f8769fb699cdb3)
І розв'яжемо для М:

де

Оскільки тепер ми маємо оцінки параметрів, і  , для основного розподілу можемо знайти точкову оцінку
, для основного розподілу можемо знайти точкову оцінку  для ймовірності успіху події i . Її можна обчислити як середнє зважене значення оцінки події
для ймовірності успіху події i . Її можна обчислити як середнє зважене значення оцінки події  і . Враховуючи наші точкові оцінки для апріора, можна підставити їхні значення, щоб знайти точкову оцінку для апостеріору
і . Враховуючи наші точкові оцінки для апріора, можна підставити їхні значення, щоб знайти точкову оцінку для апостеріору

Можемо записати апостеріорну оцінку як середньозважене:

де  називається коефіцієнтом усадки .
називається коефіцієнтом усадки .

 де
де  є дискретним рівномірним розподілом .
є дискретним рівномірним розподілом .
- Мультиноміальний розподіл Діріхле
|
|---|
| | | Дискретні одновимірні
зі скінченним носієм |
|
|---|
| Дискретні одновимірні
з нескінченним носієм |
|
|---|
| Неперервні одновимірні
з носієм
на обмеженому проміжку |
|
|---|
| Неперервні одновимірні
з носієм на напів-нескінченному
проміжку |
|
|---|
| Неперервні одновимірні
з носієм на всій дійсній прямій |
|
|---|
| Неперервні одновимірні
з носієм змінного типу |
|
|---|
| Змішані
неперервно-дискретні
одновимірні |
|
|---|
| | Багатовимірні (спільні) |
|
|---|
| | Напрямкові |
|
|---|
| | Вироджені та сингулярні[en] |
|
|---|
| | Сімейства |
|
|---|
|

